前言
本文中我们将英文rss 自动转成中文 rss供ttrss使用。(利用谷歌翻译)
方便在手机上进行阅读或者收听。

举例
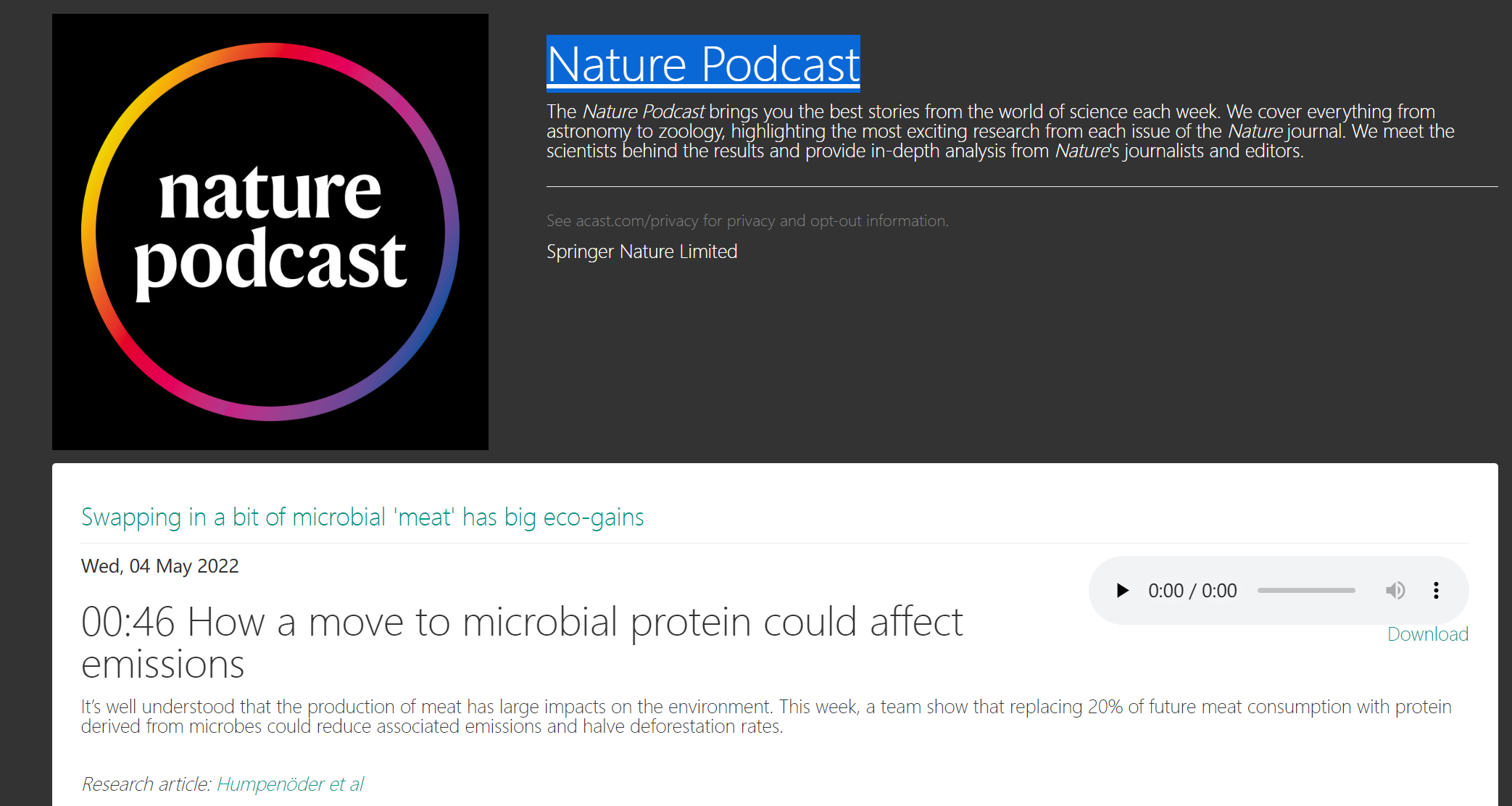
国外有很多不错的rss源,比如:
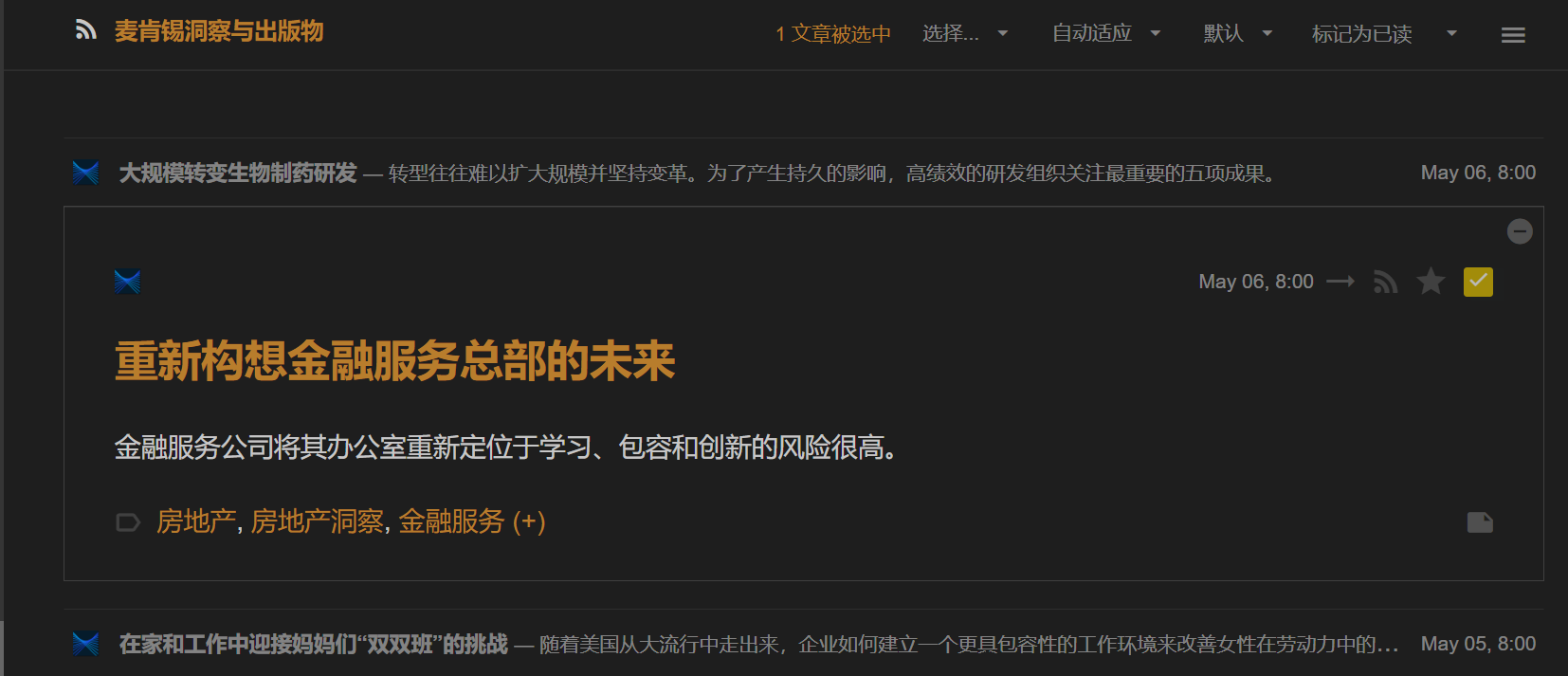
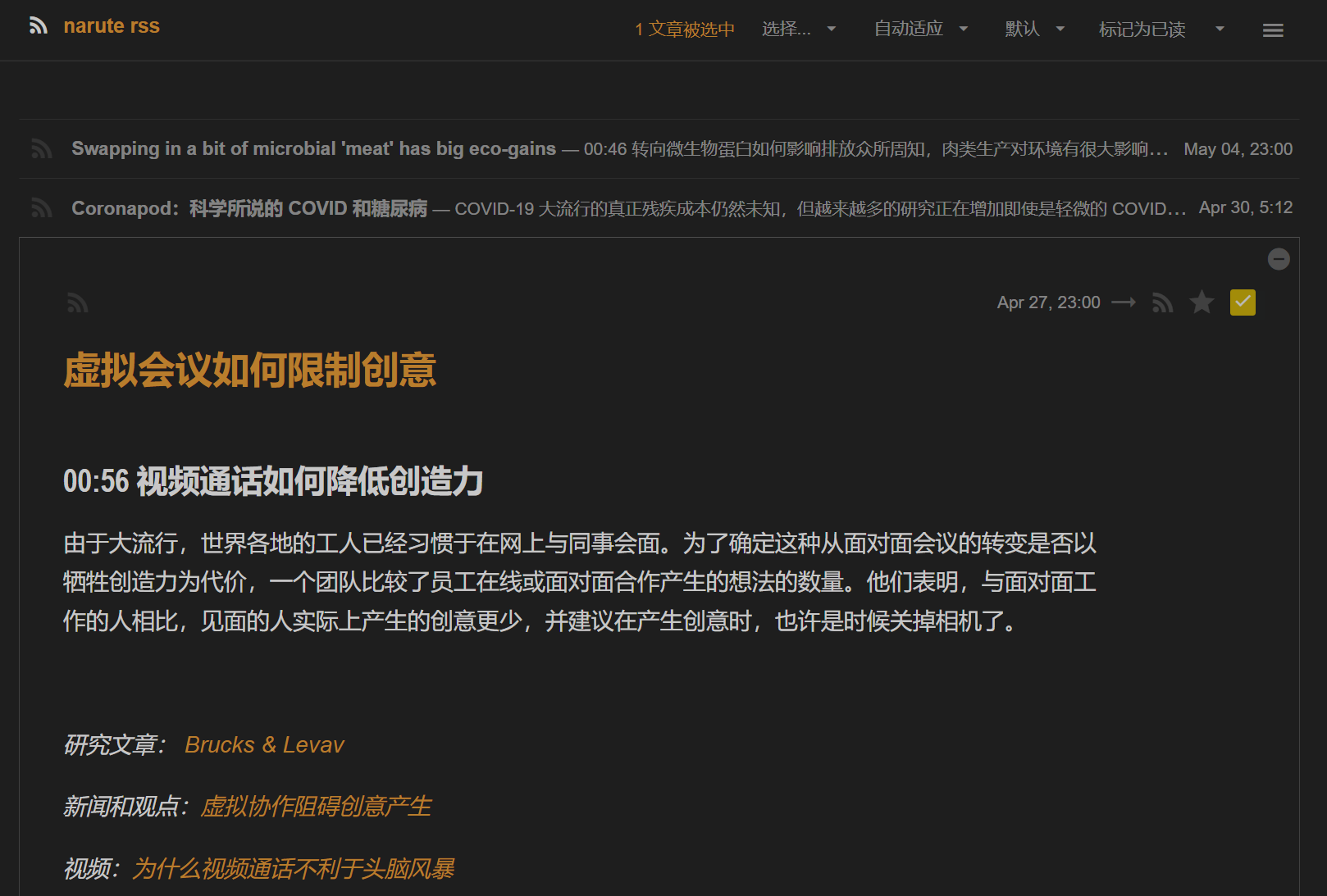
转成中文rss
脚本
使用 Translate 和 BeautifulSoup 项目
# coding:utf-8
from pygtrans import Translate
from bs4 import BeautifulSoup
# pip 安装
# pip install pygtrans BeautifulSoup -i https://pypi.org/simple
# ref:https://zhuanlan.zhihu.com/p/390801784
# ref:https://beautifulsoup.readthedocs.io/zh_CN/latest/
# client = Translate()
# text = client.translate('Google Translate')
# print(text.translatedText) # 谷歌翻译
import sys
from urllib import request
import feedparser
args = sys.argv
URL="http://www.mckinsey.com/insights/rss"
BASE="/home/xxx/www/"
def tran(url=URL,out_dir=BASE+"mckinsey_rss.xml"):
GT = Translate()
content= request.urlopen(url).read().decode('utf8')
# 变tag,以使用谷歌翻译
content=content.replace('title>', 'stitle>') #谷歌翻译会将很多titile去掉,所以需要换一个tag
content=content.replace( '<pubDate>','<pubDate><span translate="no">')
# 谷歌翻译对<span translate="no"> </span> 不翻译。
content=content.replace( '</pubDate>','</span></pubDate>')
#print(content)
_text = GT.translate(content)
with open(out_dir,'w',encoding='utf-8') as f:
c=_text.translatedText
# 还原tag
c=c.replace('stitle>', 'title>')
c=c.replace('<span translate="no">', '')
c=c.replace('</span></pubDate>', '</pubDate>')
f.write(c)
#f.write(content)
print("GT: "+ url +" > "+ out_dir)
if len(args)==1:
tran()
else:
tran(args[1],args[2])
def tran_nature(url="http://rss.acast.com/nature",out_dir=BASE+"nature_rss.xml"):
GT = Translate()
html_doc=request.urlopen(url).read().decode('utf8')
soup = BeautifulSoup(html_doc)
items=soup.find_all('item')
# nature post内容太多,谷歌api翻译不了,去掉一些
for idx,e in enumerate(items):
if idx >8:
e.decompose()
content= str(soup)
content=content.replace('title>', 'stitle>')
content=content.replace( '<pubdate>','<pubDate><span translate="no">')
content=content.replace( '</pubdate>','</span></pubdate>')
#print(content)
_text = GT.translate(content)
with open(out_dir,'w',encoding='utf-8') as f:
c=_text.translatedText
c=c.replace('stitle>', 'title>')
c=c.replace('<span translate="no">', '')
c=c.replace('</span></pubdate>', '</pubDate>') # 对于ttrss需要为pubDate才会识别正确
c=c.replace('>','>') # > 会影响识别
f.write(c)
#f.write(content)
print("GT: "+ url +" > "+ out_dir)
tran_nature()
定时任务
注意激活一下miniconda3 这个命令
source /home/xxx/miniconda3/bin/activate
放到 /etc/cron.daily/
#!/bin/bash
source /home/xxx/miniconda3/bin/activate
python /home/xxx/txxx.py