前言 本正则化系列文章我们将讨论正则化技术在机器学习和深度学习的应用。本文为该系列的第一篇,主要介绍机器学习正则化的概念,原理和应用实例。
正则化 技术广泛应用在机器学习和深度学习算法中,本质作用是防止过拟合、提高模型泛化能力。其中过拟合的简单理解就是训练的算法模型太过复杂,模型过分考虑了当前样本的结构。
在早期的机器学习领域一般只是将范数惩罚叫做正则化技术,而在深度学习领域认为,能够显著减少方差,而不过度增加偏差的策略都可以认为是正则化技术。故推广的正则化技术还有:扩增样本集、早停止、Dropout、集成学习、多任务学习、对抗训练、参数共享等。(具体见“花书 第七章 Regularization for Deep Learning”),关于深度学习正则化会在下一篇正则化文章中重点分析。
转载自:https://blog.csdn.net/BigData_Mining/article/details/81631249
¶1. 多角度看机器学习正则化
机器学习领域正则化可以从以下三个角度进行理解:
(1) 正则化等价于结构风险最小化,其是通过在经验风险项后加上表示模型复杂度的正则化项或惩罚项,达到选择经验风险和模型复杂度都较小的模型目的。
经验风险:机器学习中的风险是指模型与真实解之间的误差的积累,经验风险是指使用训练出来的模型进行预测或者分类,存在多大的误差,可以简单理解为训练误差,经验风险最小化即为训练误差最小。
结构风险:结构风险定义为经验风险与置信风险(置信是指可信程度)的和,置信风险越大,模型推广能力越差。可以简单认为结构风险是经验风险后面多加了一项表示模型复杂度的函数项,从而可以同时控制模型训练误差和测试误差,结构风险最小化即为在保证模型分类精度(经验风险)的同时,降低模型复杂度,提高泛化能力。
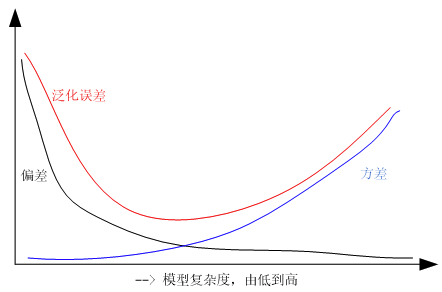
公式表达 $$ R(f)=\frac{1}{n}\sum_{i=1}^{n}L(y_i,f(x_i)) + \lambda \Omega (f) \tag{1} $$ 其中,$R(f)$表示结构风险,$L(y_i,f(x_i))$表示第 $i$ 个样本的经验风险,$\Omega(f)$是表征模型复杂度的正则项,$\lambda$ 是正则化参数。根据奥姆剃刀定律,“如无必要,勿增实体”,即认为相对简单的模型泛化能力更好。而模型泛化能力强、泛化误差小,即表示模型推广能力强,通俗理解就是在训练集中训练得到的优秀模型能够很好的适用于实际测试数据,而不仅仅是减少训练误差或者测试误差。泛化误差定义如下: $$ E={Bias}^2(X) + {Var}(X) +{Noise} \tag{2} $$ 其中,$E$ 表示泛化误差,${Bias}$ 代表偏差,${Var}$ 代表方差, ${Noise}$ 代表噪声。
关系图
(2) 正则化等价于带约束的目标函数中的约束项
以平方误差损失和L2范数为例,优化问题的数学模型如下: $$ J(\theta)=\sum_{i=1}^{n}(y_i-\theta^Tx_i)^2 \tag{3} $$ $$ {s.t.}{|| \theta ||}_2^2 \leq C\
\tag{4} $$
针对上述约束条件的优化问题,采用拉格朗日乘积算子法可以转化为无约束化问题,即 $$ J(\theta)=\sum_{i=1}^{n}(y_i-w^Tx_i)^2 + \lambda({|| \theta ||}_2^2-C) \tag{5} $$
由于参数 $C$ 为常数,可以忽略,故上述公式和标准的正则化 公式完全一致。
(3) 从贝叶斯角度考虑
正则项等价于引入参数的模型先验概率,可以简单理解为对最大似然估计引入先验概率,从而转化为最大后验估计,其中的先验概率即对于正则项(这部分内容后面详细讲解)。
¶2 基本概念
正则化也可以成为规则化、权重衰减技术,不同的领域叫法不一样,数学上常用范数实现,例如L1和L2范数,统计学领域叫做惩罚项、罚因子。
下面给出范数的数学公式,方便以后分析:
(1) $p$ 范数: $$ Lp=(\sum_{i=1}^{n}{|| x_i ||}^p)^{\frac{1}{p}} \tag{6} $$ (2) $L0$ 范数:0 范数表示向量中非零元素的个数(即为其稀疏度)
(3) $L1$ 范数:即向量元素绝对值之和,$p$ 范数取1,即为1范数 $$ {||x||}_1=\sum^n_1 {|| x_i || } \tag{7} $$
(4) $L2$ 范数:即向量元素绝对值的平方和再开发,也称欧几里得距离,$p$ 范数取2,即为2范数 $$ {||x||}_{2}=\sqrt{\sum^{n}_1|| x_i ||^2} \tag{8} $$
(5) $\infty $ 范数:即所有向量元素的绝对值中的最大值,$p$ 范数取 $\infty $,即为 $\infty $ 范数 $$ {||x ||}_{\infty }=\underset{i}{\max}{\left | x_i \right |} \tag{9} $$
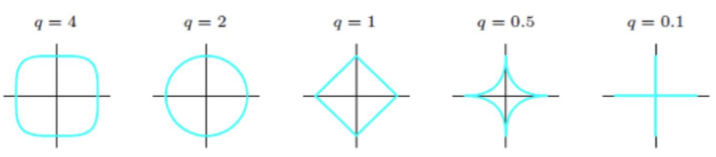
(6) $-\infty $ 范数:即所有向量元素绝对值中的最小值,$p$ 范数取$-\infty $,即为 $-\infty $ 范数 $$ {||x ||}_{-\infty }=\underset{i}{\min}{\left | x_i \right |} \tag{10} $$ 图形描述
从 Fig 2、Fig 3 图可以看出:q(p)越小,曲线越贴近坐标轴,q(p)越大,曲线越远离坐标轴,并且棱角越明显,当q(p)取0时候,是完全和坐标轴贴合,当q(p)取无穷的时候,呈现正方体形状。同时也可以看出,采用不同的范数作为正则项,会得到完全不同的算法模型结果,故而对于不同要求的模型,应该采用不同的范数作为正则项。
为了更好的理解正则化技术原理,下面从4个方面进行深度分析,希望对大家理解有帮助。
¶3.1 简单数值假设分析法
此处以L2范数讲解,下面的各图形来自吴恩达的机器学习课程。
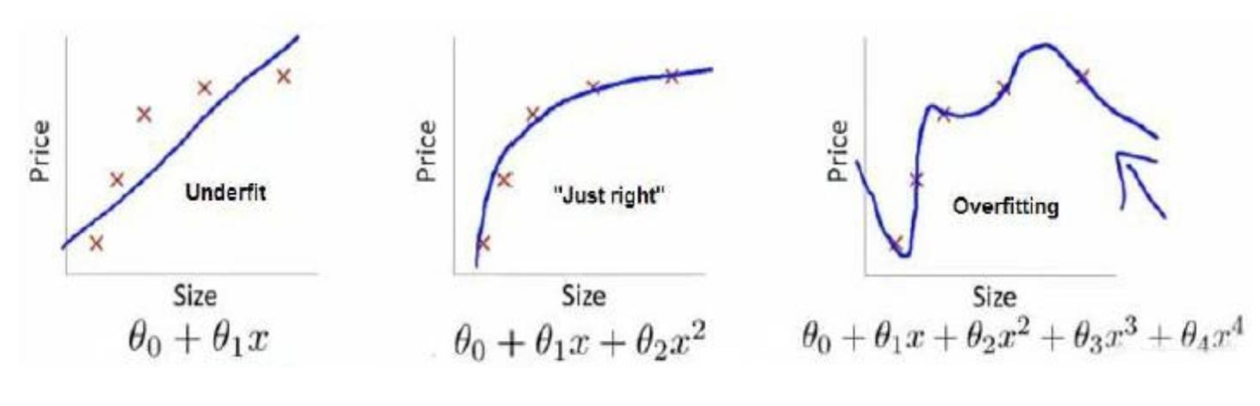
¶3.2 图形分析法
此处采用L1和L2范数讲解: (1) L2 范数正则 $$ J(\beta)=\sum_{i=1}^{n}(y_i-{\beta}^T x_i)^2 + \lambda {|| {\beta} ||}_2^2 \tag{14} $$ 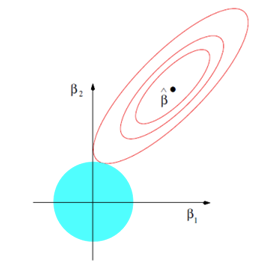
¶4. 贝叶斯角度分析
以L1和L2范数为例,所得结论可以推广到P范数中,首先需要知道:整个最优化问题从贝叶斯观点来看是一种贝叶斯最大后验估计,其中正则化项对应后验估计中的先验信息,损失函数对应后验估计中的似然函数,两者的乘积即对应贝叶斯最大后验估计的形式。针对L1和L2范数还有结论:L2 范数相当于给模型参数设置一个协方差为1/alpha的零均值高斯先验分布,L1 范数相当于给模型参数 设置一个参数为1/alpha 拉普拉斯先验分布。
为了讲清楚上述结论,需要具备几点前置知识点:(1) 高斯分布和拉普拉斯分布的定义和形状;(2) 贝叶斯定理;(3) 最大似然估计;(4) 最大后验估计。下面我对这4个知识点进行解释。
(1) 高斯分布和拉普拉斯分布
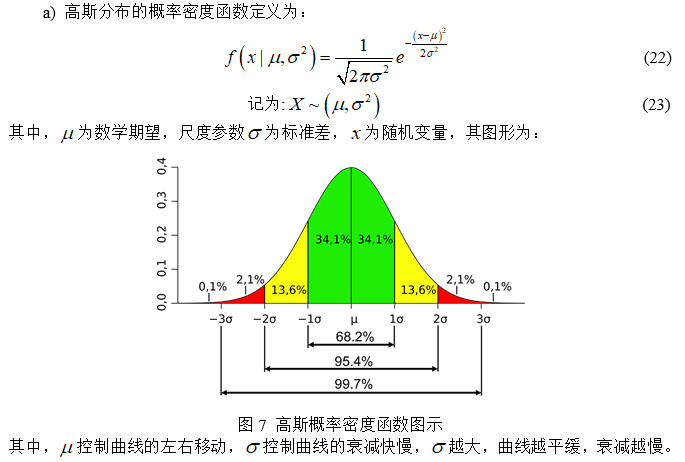
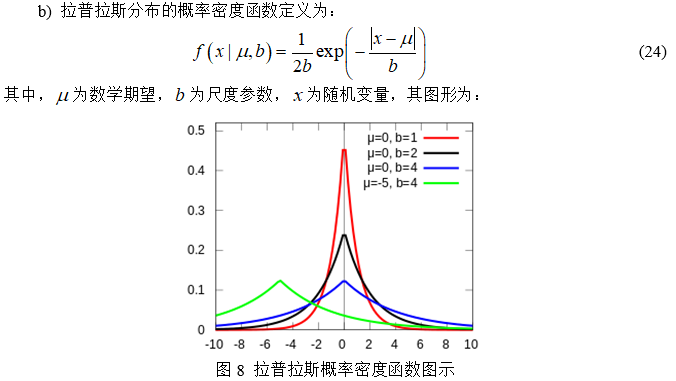
(2) 最大似然估计

如果上述公式不能理解,请各位读者去复习一下大学课程《概率论与数理统计》中的参数估计章节,为了更方便理解,下面举一个例子:假设我要统计出整个大学内所有同学的身高分布情况,设全校一共20000人,数量庞大,所有人都去问一遍不太靠谱,所以我打算采用抽样方法来估计,假设我已经知道身高分布服从高斯分布,但是我不知道高斯分布中的均值和方差参数,现在我打算采用最大似然估计方法来确定这两个参数。首先需要明确,全校20000即为总体X,我随机从各个班抽取10名同学,假设一共抽了2000个同学,那么2000同学就构成了样本空间,由于每个样本的概率密度函数已知,则很容易写出似然函数,对数求导即可求解参数。
(3) 最大后验估计



¶5. 例子
¶5.1 逻辑回归
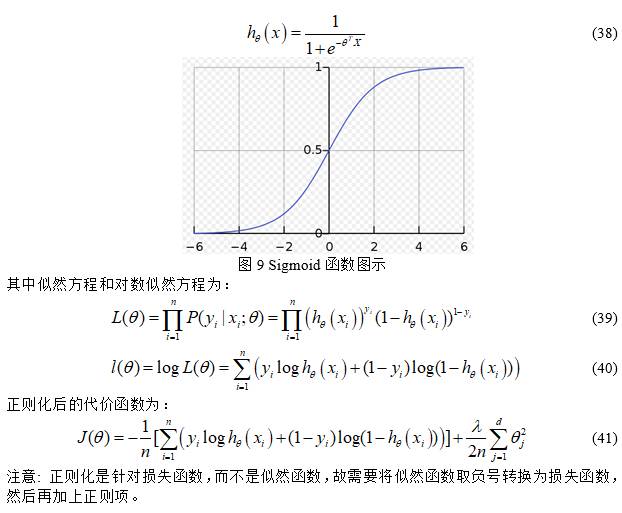
二分类逻辑回归使用Sigmoid作为决策函数进行分类,该函数可以将任意的输入映射到[0,1]区间,当预测结果小于0.5,则表示负类,当预测结果大于0.5.则表示正类,其模型本质是求最大似然估计,具体求解似然函数通常使用梯度下降法,而前面说过:最大似然估计法没有考虑训练集以外的因素,很容易造成过拟合,故而逻辑回归一般采用L2范数进行正则化操作,Sigmoid函数定义和图形如下:
¶5.2 岭回归(Ridge Regression)
岭回归本质上是针对线性回归问题引入了L2范数正则,通过缩减回归系数避免过拟合问题,最先用来处理特征数多于样本数的情况(高维小样本问题),现在也用于在估计中加人偏差,从而得到更好的估计,加了正则化后的代价函数如下:

¶5.3 Lasso 回归
拉索回归(lasso回归)本质上是针对线性回归问题引入了L1范数正则,通过缩减回归系数避免过拟合问题,其不同于L2范数,其可以将某些系数缩减为0即所谓的具备稀疏性(稀疏性的好处是简化计算、容易理解模型、减少存储空间、不容易出现过拟合等等),加了正则化后的代价函数如下:
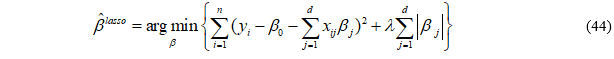
其中,参数函数和岭回归中相同。L1范数罚有一个问题:由于|X|函数在0处不可导,故而直接使用最小二乘法、梯度下降法等方法均失效,但是由于其为第一类间断点中的可去间断点,可以通过补充该点的定义解决,通常,对于线性回归中的lasso回归可以采用近似的前向逐步回归替代。
¶5.4 SVM
支持向量机SVM优化目的为寻找一个超平面,使得正负样本能够以最大间隔分离开,从而得到更好的泛化性能,其通过引入核函数来将低维线性不可分的样本映射到高维空间从而线性可分,通过引入惩罚参数C(类似于正则化参数)来对错分样本进行惩罚,从而减少模型复杂度,提高泛化能力,其优化目标如下:
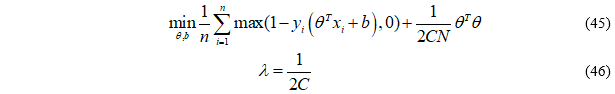
大家如果不知道上面公式的推导,不用紧张,对于本次内容不是重点,只需要关注后面正则项部分,惩罚参数C作用和正则化参数作用一致,只是反相关而已。需要明白以下结论:
(1) C越大,正则化参数越小,表示对分错样本的惩罚程度越大,正则化作用越小,偏差越小,方差越大,越容易出现过拟合(通俗理解,原本将低维空间映射到5维空间正好线性可分,但是由于惩罚过于严重,任何一个样本分错了都不可原谅,结果系统只能不断提高维数来拟合样本,假设为10维,最终导致映射维数过高,出现过拟合样本现象,数学上称为VC维较大);
(2) C越小,正则化参数越大,表示对分错样本的惩罚程度越小,正则化作用越大,偏差越大,方差越小,越容易出现欠拟合(通俗理解,原本将低维空间映射到5维空间正好线性可分,但是由于惩罚过小,分错了好多样本都可以理解,比较随意,结果系统也采用简化版来拟合样本,假设为3维,最终导致映射维数过低,出现欠拟合样本现象,数学上称为VC维较小)。
¶6. 总结
根本目的本质:防止过拟合,提高模型泛化能力。
正则化技术分类: 狭义上(不同地方叫法不同)
- 在早期的机器学习领域一般只是将范数惩罚叫做正则化技术
- 规则化、权重衰减
- 从贝叶斯角度考虑,正则项等价于引入参数的模型先验概率
广义上: 能够显著减少方差,而不过度增加偏差的策略都可以认为是正则化技术,推广的正则化技术还有:扩增样本集、早停止、Dropout、集成学习、多任务学习、对抗训练、参数共享等。