¶前言
本文中我们将英文rss 自动转成中文 rss供ttrss使用。(利用谷歌翻译)
方便在手机上进行阅读或者收听。

¶举例
国外有很多不错的rss源,比如:
转成中文rss
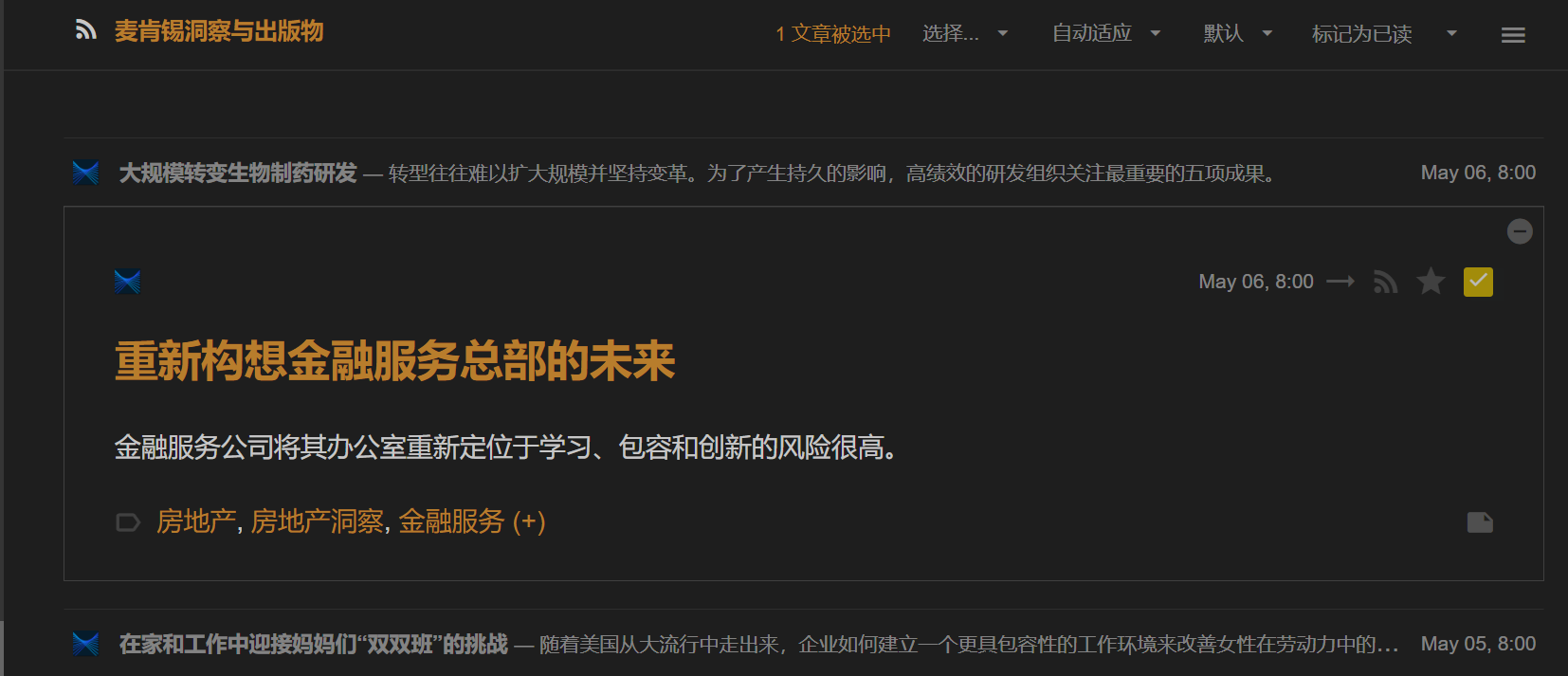
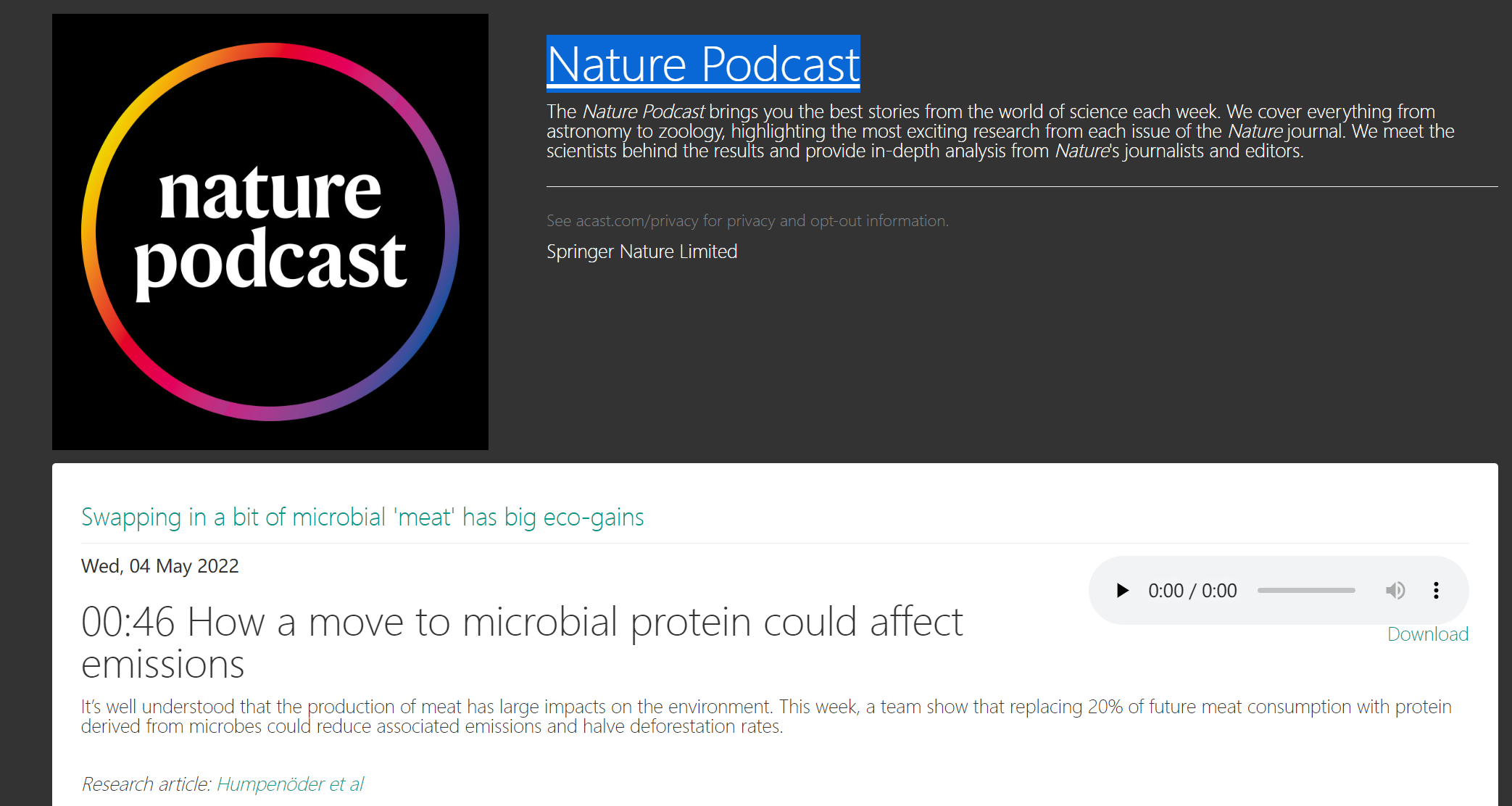
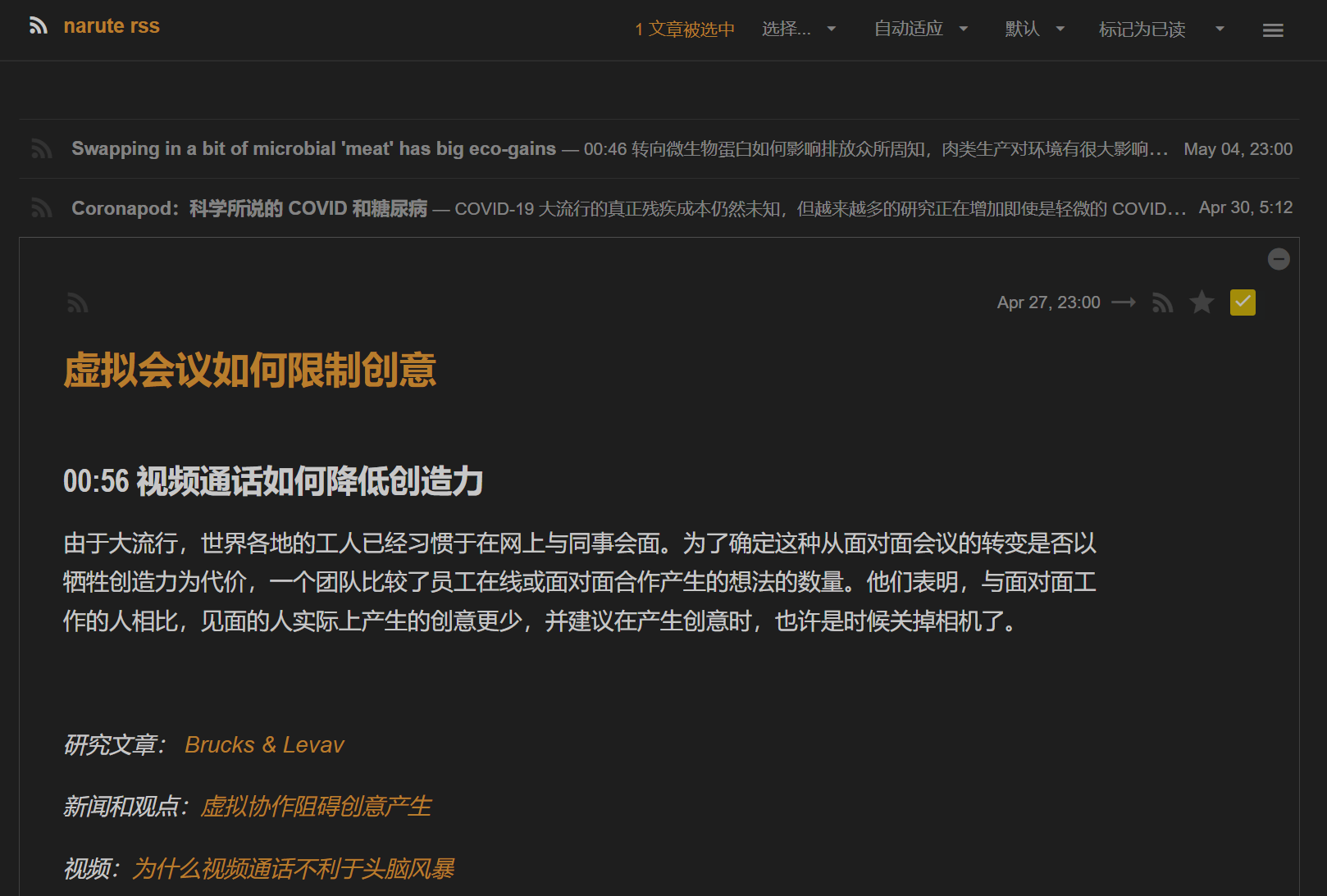
¶脚本
使用 Translate 和 BeautifulSoup 项目
1 | # coding:utf-8 |
¶定时任务
注意激活一下miniconda3 这个命令
source /home/xxx/miniconda3/bin/activate
放到 /etc/cron.daily/
1 |
|
本文中我们将英文rss 自动转成中文 rss供ttrss使用。(利用谷歌翻译)
方便在手机上进行阅读或者收听。
国外有很多不错的rss源,比如:
转成中文rss使用 Translate 和 BeautifulSoup 项目
1 | # coding:utf-8 |
注意激活一下miniconda3 这个命令
source /home/xxx/miniconda3/bin/activate
放到 /etc/cron.daily/
1 |
|