文件head,设置标题、日期、分类、标签、评论、版权、是否使用公式,如下。
1 | --- |
摘要
本部分说明文章的写作意图。涉及的背景、主要内容、本文与其他文章关系等。
本文为Hexo博客模版文件,以Markdown语言书写。
1 | 前言一般放到主页,可利用 <!-- more --> 隔断。 |
文件head,设置标题、日期、分类、标签、评论、版权、是否使用公式,如下。
1 | --- |
摘要
本部分说明文章的写作意图。涉及的背景、主要内容、本文与其他文章关系等。
本文为Hexo博客模版文件,以Markdown语言书写。
1 | 前言一般放到主页,可利用 <!-- more --> 隔断。 |
前言
路漫漫其修远兮,吾将上下而求索。2013年,大二接触人工智能课,讲逻辑推理,专家系统等等,神经网络只是一部分,打开当时老师的ppt,还能看到BP等算法。接着在2015年,上了模式识别课程,有一些启发式算法,KNN K-means等算法,同时神经网络也已经有了 GoogLeNet 等深层网络,热门的GAN网络也在2014年被提出。后面,机遇巧合,本科毕业时选了人工智能的坑,直到3年后的现在算是明白了一点。接下来的三年的目标还是 成为一名优秀的算法工程师。
回望入坑 机器学习,没有系统地整理过相关知识。于是想着手整理一份自己笔记系列。本文为序。
雄关漫道真如铁,而今迈步从头越。
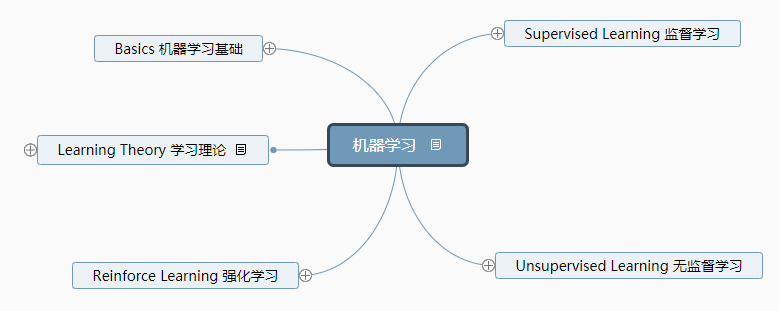
前言
《形象美学》这本书是我偶然间看到的,本人很少买衣服,自认为衣品极差,被老妈诟病。以前的观点是多买,买一些品牌好的。每当要去买衣服的时候(计划一年两次),总是有很多困扰。图书馆看到此书,恰合我意,翻阅全书,或许有望提高衣品,提升人生品味了,哈哈哈。
此书的作者是一位研究人物形象设计的大学教师,并有着多年服装顾问的实战经验。书前四章有很多服装的基础理论,搭配等技巧,书后两章给出驭装的细节方法和一个必备的衣服仓库的采购整理建议。本博文中将整理书中的重点,供各位同好们参考。
此书历经10 年完成(书中官方介绍),分为塑型、悦色、妆饰、驭装、理橱、博雅六个章节。书本主要分析了衣服的材质、款式、色彩、场合,以期帮助读者从尊重、认识、爱上自己的长相与身材开始,到认识与识别商品进行实践,最终达到人衣匹配,内外合一的境界。