¶摘要
日常生活中,我们面临很多的选择,选择自己最工作offer,选择买哪个牌子的手机,选择哪个地方旅行等等。这些选择难以定量的衡量,有很多不确定性。内心小纠结,我选择了这个,万一那个好呢,怎么办?请看层次分析法。
层次分析法(Analytic Hierarchy Process,简称 AHP)是对一些较为复杂、较为模糊的问题作出决策的简易方法,它特别适用于那些难于完全定量分析的问题。它是美国运筹学家 T. L. Saaty 教授于上世纪 70 年代初期提出的一种简便、灵活而又实用的多准则决策方法。
运用层次分析法建模,大体上可按下面四个步骤进行
- 建立递阶层次结构模型
- 构造出各层次中的所有判断矩阵
- 层次单排序及一致性检验
- 层次总排序及一致性检验。(一般不用)
让我们从offer大佬的例子开始吧!
举个栗子,今年有位大学生,有三个offer,C1 C2 C3。
第一步,建立层次模型。
- 目标层A:找工作的目标,自己满意程度。
- 这个程度怎么计算呢?比如工作1。
- 准则层B:研究课题、发展前途、待遇、同事情况、地理位置、单位名气等等。
- 尽量列全一点,不需要排列重要顺序。
- 小于等于9个,后面要两两拍脑袋给出相对的重要层度,给多了不得把脑袋拍疼了。
- 也可以有子准则层,比如待遇中的放假、工作环境等等,列出也小于9个。
- 方案层C:就是我们的offer
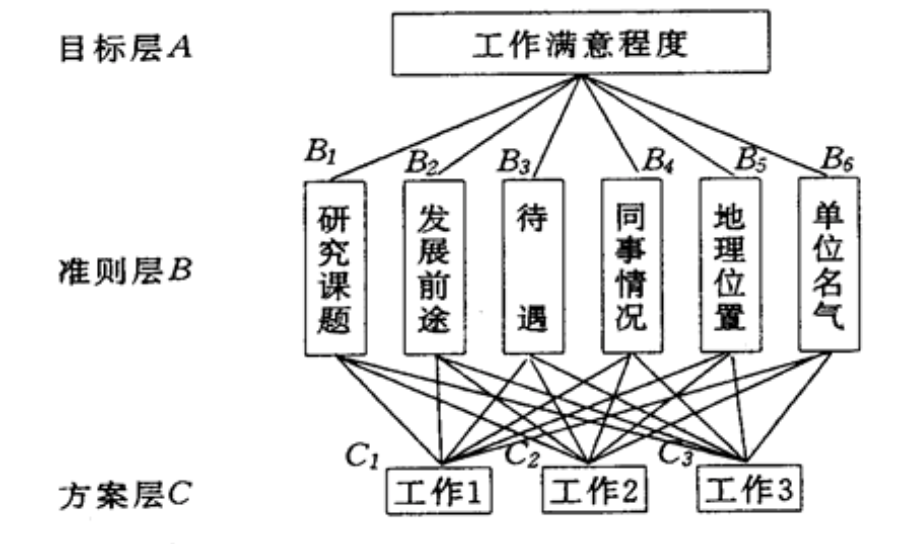
¶构造 A B 之间判断矩阵
准则层B与目标A之间的关系。为了求出准则层中(B1-6) 对目标的重要层度的排序。比如对于该生工作满意度第一重要是待遇,然后是地点,其实该生自己也很模糊。就是固定A,然后求B中准则,对A重要性的排序。
¶我们怎么对B中的准则们的重要排序呢?
直接给每一个准则,0-1的评分,然后排序。经常会想,给完分之后,这个不合理呀要不我再给哪个准则加加分。所以这样的方法常常会因考虑不周全、顾此失彼而使决策者提出与他实际认为的重要性程度不相一致的数据。
我们可以将这个过程细化,我就比较两个准则对于目标的重要性,然后通过下面的矩阵方法,求出优先顺序。
还能通过一个一致性检验,来检验在你评分的过程中,有没有自相矛盾的地方,当然这种方法允许一些自相矛盾。反正评分的时候尊从内心拍脑袋就对了。
所以我们拿出一个B1 与 B2 对于目标的重要,想一想然后给出B2/B1,填入下面的表格中的(2,1)的位置。
整个矩阵i,j 与j,i 是取倒数的关系,所以只要做一半。
在找工作的目标下,准则i与j相对的重要性表示,B2/B1 的值。采用9个标度。而相比不重要刻度取倒数就可以了
| 准则i比j的比较 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| 相同重要 | 比较重要 | 明显重要 | 强烈重要 | 极端重要 |
最后的两两相对重要表格
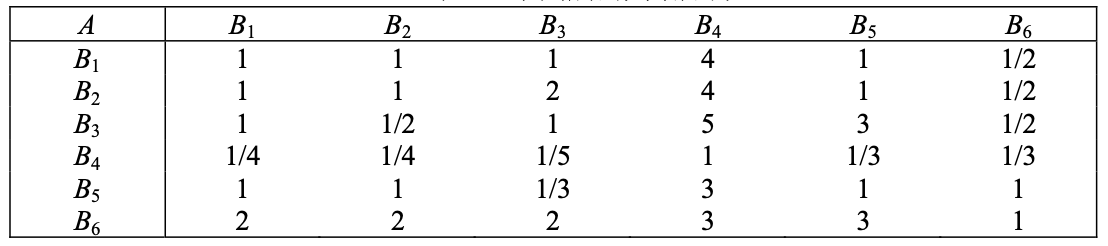
对角线对称的两个数互为倒数,即 $$a_{ji}=\frac{1}{a_{ij}}$$ B1/B2 不就是和 B2/B1互为倒数嘛
从心理学观点来看,分级太多会超越人们的判断能力,既增加了作判断的难度, 又容易因此而提供虚假数据。Saaty 等人还用实验方法比较了在各种不同标度下人们判断结果的正确性,实验结果也表明,采用 1~9 标度最为合适。
判断矩阵的一致性指标步骤:
- 1)计算一致性指标 CI 。$$CI=\frac{ \lambda_{max}-n}{n-1}$$
- 2)查表,平均随机一致性指标 RI。
| n | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| RI | 0 | 0 | 0.58 | 0.90 | 1.12 | 1.24 | 1.32 | 1.41 | 1.45 |
RI 的值是这样得到的,用随机方法构造500个样本矩阵:随机地从1~9及其倒数中抽取数字构造正互反矩阵,求得最大特征根的平均值 $$\bar \lambda_{max}$$ 并定义$$RI=\frac{\bar \lambda_{max}-n}{n-1}$$
- 3)计算一致性比例CR。 $$CR=\frac{CI}{RI}$$,当$$CR<0.10$$ 时,认为判断矩阵的一致性是可以接受的,否则应对判断矩阵作适当修正。
如果一个矩阵满足上面的条件,那么它最大特征值对应的特征向量就可以认为是每个维度的重要性权重。
¶构造 B C 之间判断矩阵
相同的方法,在同一B准则下,考虑不同工作的优先顺序。求工作排序的方法,和上面一样。

python代码[1]
1 | import numpy as np |
¶层次分析法与控制变量法
我们的任务是选择工作,最后使得我们满意,直接选择我们当然一头雾水。所以我们设立一些准则,然后对这些准则对于目标的重要性排序。
这又有点像概率图模型,只是赋权的方法,是相互比较的方法。
¶选择困难者的福音?
层次分析法对人们的思维过程进行了加工整理,提出了一套系统分析问题的方法,为科学管理和决策提供了较有说服力的依据。
在应用层次分析法研究问题时,遇到的主要困难有两个:
(1) 如何根据实际情况抽象出较为贴切的层次结构;
(2) 如何将某些定性的量作比较接近实际定量化处理。
层次分析法的其局限性[2]:
(1) 它在很大程度上依赖于人们的经验,主观因素的影响很大,它至多只能排除思维过程中的严重非一致性,却无法排除决策者个人可能存在的严重片面性。
(2) 比较、 判断过程较为粗糙,不能用于精度要求较高的决策问题。
所以,AHP 至多只能算是一种半定量(或定性与定量结合)的方法。 本文仅供参考,不负法律责任,哈哈。
¶参考
幼鹰me 知乎 层次分析法原理与Python实现 ↩︎
司守奎《数学建模算法与程序》第八章 层次分析法 P167 ↩︎